Advertisement
Python offers multiple ways to convert a string into bytes, and each method suits a specific situation. Whether you're handling file I/O, working with network data, or preparing information for encryption, converting a string to bytes becomes essential. This isn't a one-size-fits-all scenario. Different needs call for different techniques. So, let's get right into it—with no repeats and no fuss.
This is by far the most direct and preferred way when working with strings. Python strings come with an encode() method, which returns a bytes object. You just pass the encoding you want to use—most commonly 'utf-8'.
python
CopyEdit
text = "Hello, world"
byte_data = text.encode('utf-8')
You can also use other encodings like 'ascii', 'utf-16', or 'latin1', depending on what you need. If your string includes characters not supported by the encoding, it will raise a UnicodeEncodeError unless you handle it with the errors argument.
python
CopyEdit
byte_data = text.encode('ascii', errors='ignore')
It’s simple, clean, and works well for most cases where text needs to be serialized or sent over a network.
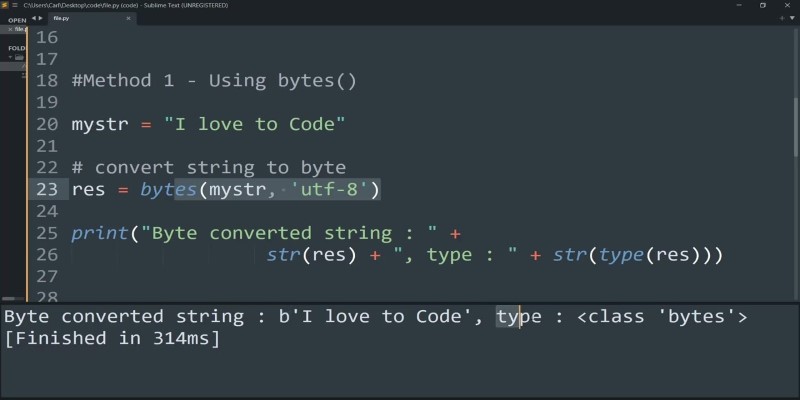
Another way to get bytes from a string is by using the bytes() constructor. This method also expects an encoding to be passed in, just like encode().
python
CopyEdit
text = "Python"
byte_data = bytes(text, encoding='utf-8')
Internally, this behaves quite like encode(), but it gives you slightly more flexibility in some contexts, especially when you're dynamically constructing bytes and need to use positional arguments.
You can also write it like this:
python
CopyEdit
byte_data = bytes("Python", "utf-8")
If you forget the encoding, Python will raise a TypeError, reminding you that the conversion isn’t automatic.
The bytearray() constructor is similar to bytes(), except it returns a mutable sequence of bytes. If you’re planning to manipulate the resulting bytes later (modify individual bytes, append, etc.), this is the way to go.
python
CopyEdit
text = "Mutable bytes"
mutable_bytes = bytearray(text, 'utf-8')
The usage is nearly identical to bytes() with strings. But keep in mind: once you have a bytearray, it can be converted back to bytes if needed:
python
CopyEdit
immutable_bytes = bytes(mutable_bytes)
So, if mutability is part of your requirement, this path makes sense.
It might seem like this was already covered, but the focus here is on experimenting with other encodings for specific scenarios. While 'utf-8' is standard, others can be useful depending on what the receiving system expects.
For example:
python
CopyEdit
text = "Café"
byte_data_utf16 = text.encode('utf-16')
byte_data_latin1 = text.encode('latin1', errors='replace')
You might use 'utf-16' when interfacing with systems like Windows APIs, or 'latin1' for older protocols or databases.
Choosing the correct encoding matters when compatibility is key. Though the method used here is the same encode(), the output format changes entirely based on the encoding, which can affect file sizes, data integrity, or readability on the other side.
If you’re working with large strings and need to avoid copying data repeatedly, memoryview() can be helpful. Though it's not directly used for converting strings, combining it with byte conversion is quite efficient.
python
CopyEdit
text = "Efficient string"
byte_data = text.encode('utf-8')
mem_view = memoryview(byte_data)
Now, mem_view holds a view of the bytes. This approach is suitable for buffer operations and when you need to slice or manipulate bytes without creating multiple copies in memory.
You can later retrieve the original bytes like this:
python
CopyEdit
original_bytes = mem_view.tobytes()
This isn't a primary conversion technique, but it becomes useful when efficiency is a concern during string-to-byte operations.
Sometimes you need to convert a string to bytes for transmission over a channel that only supports ASCII-safe content. In such cases, encoding to Base64 is common. Here’s how to do it using Python's built-in base64 module.
python
CopyEdit
import base64
text = "Secure data"
byte_string = text.encode('utf-8')
base64_bytes = base64.b64encode(byte_string)
The result here is still in bytes, but it represents the Base64-encoded version of your original string. This is helpful when you need to pass binary content over text-only media.
To decode it back:
python
CopyEdit
decoded_bytes = base64.b64decode(base64_bytes)
original_text = decoded_bytes.decode('utf-8')
Keep this method in your toolkit when ASCII-safe encoding is needed, especially for web data or email attachments.
If you ever need to control exactly how each character is turned into bytes (for educational purposes or highly specific encoding schemes), you can convert characters using ord() and manually build a bytes object.
python
CopyEdit
text = "ABC"
byte_list = [ord(char) for char in text]
byte_data = bytes(byte_list)
This only works for ASCII-range characters (0–127), since ord() returns Unicode code points, and bytes() expects values between 0 and 255. For anything beyond standard English characters, this won’t hold up without additional logic.
Still, it’s a straightforward way to see what’s happening under the hood when encoding strings.
If you're working with more than just plain text—say, Python objects that include strings, numbers, or even custom classes—you can convert them into bytes using the pickle module. While this method isn't meant for standard string encoding, it technically converts a string into bytes by serializing it.
python
CopyEdit
import pickle
text = "Pickle this string"
byte_data = pickle.dumps(text)
The result is a bytes object that represents the serialized form of the string. This approach is useful when you plan to store or transmit data that will be deserialized later using pickle.loads():
python
CopyEdit
original_text = pickle.loads(byte_data)
Keep in mind that the bytes from pickle.dumps() are not human-readable and are meant for Python internal use. This method is overkill for simple string encoding, but it is useful in cases where strings are part of larger data structures.
Converting a string to bytes in Python can be as simple or as specialized as your task requires. Whether you want a quick encode() call or need to wrap the result in a memory view or send it as Base64, Python provides the tools. The key is choosing the method that aligns with your end goal—immutability, compatibility, size, or safety. Every method in this list does something slightly different, and when applied thoughtfully, it leads to cleaner, more reliable code.
Advertisement

Discover the risks of adversarial attacks in machine learning and how researchers are developing countermeasures.
Need to convert bytes to a readable string in Python? Explore 7 clear and practical methods using .decode(), base64, io streams, memoryview, and more

Discover Microsoft’s Responsible AI suite: fairness checks, explainability dashboards, harmful content filters, and others
Learn how to create a list of dictionaries in Python with different techniques. This guide explores methods like manual entry, list comprehensions, and working with JSON data, helping you master Python dictionaries

Unlock the power of Python’s hash() function. Learn how it works, its key uses in dictionaries and sets, and how to implement custom hashing for your own classes

Getty Images launches a rights-safe AI image tool to ease artist concerns over copyright and ethical AI use

Discover how insurance providers use AI for legal contract management to boost efficiency, accuracy, risk reduction, and more

Find how red teaming secures large language models against threats, vulnerabilities, and misuse in AI-driven environments.

Learn how Microsoft expands Azure AI Studio with GenAI tools to deliver smarter and more scalable AI solutions for everyone.

Here’s a breakdown of regression types in machine learning—linear, polynomial, ridge and their real-world applications.

Meta launches an advanced AI assistant and studio, empowering creators and users with smarter, interactive tools and content

Discover how generative AI is set to revolutionize enterprise operations, from productivity to innovation and beyond